DayCarat 인프라 구조 설계: 내가 한 달 만에 설계부터 구현까지 성공적으로 마칠 수 있었던 이유
DayCarat 인프라 구조 설계: 내가 한 달 만에 설계부터 구현까지 성공적으로 마칠 수 있었던 이유

올해 2월까지 DayCarat 서비스 개발을 담당했습니다.
설계 중 많은 고민 사항이 있었고, 저처럼 프로젝트를 시작하는 입장에서 고려할 만한 방법이 어떤 것이 있을지 공유해 드리고자 다음 게시글을 작성했습니다.
요구사항 파악하기
CMC 14기로 활동하며 구성된 팀에서 만든 서비스로, 설계 당시 여러 요구사항이 있었습니다.
- 관계형 데이터베이스에서 여러 테이블을 두고 복잡한 쿼리를 작업할 수 있는 구조를 가질 것
- 모두에게 보내는 공지사항 알림 뿐 아니라 특정 작업 완료 시 개인에게 보내는 알림 서비스를 구현할 것
- 외부 API(GPT)를 호출할 수 있고, 이는 비동기적으로 호출할 것
- 팀원과 원활한 소통을 할 수 있도록 고려할 것
서버를 설계하는 입장에서 이 외에도 기본적으로 갖추어야 할 암시적 요구사항도 있었습니다.
- 서버 비용을 지원받지 않으므로 최대한 비용 효율적으로 설계할 것
- 짧은 개발 기간을 가지므로 빠르게 구현할 수 있도록 설계할 것
- 유저 트래픽 증가에 대응할 수 있도록 확장 가능성을 열어둘 것
- 단일 장애 지점을 회피한 설계를 할 것
- 안전한 환경을 구축할 것
이런저런 요구사항이 있었습니다. 이것들을 다 만족하려면 쉽지 않겠다는 생각이 들었습니다.
차근차근 하나씩 생각해 보기로 합시다.
1. 관계형 데이터베이스에서 여러 테이블을 두고 복잡한 쿼리를 작업할 수 있는 구조를 가질 것

DB와 연결하여 복잡한 쿼리를 날려야 하는데, Spring boot를 이용해 QueryDSL을 사용한 경험이 있기 때문에 이를 이용하고자 했습니다. 제가 보유한 기술 스택 중 가장 익숙하여 빠르게 구현할 수 있는 것을 채택하였습니다.
ALB - EC2 - RDS 를 사용하기로 합니다:
- t2.micro 프리티어 인스턴스와 RDS t3.micro 프리티어 인스턴스 를 사용하기에 비용이 발생하지 않습니다.
- 익숙한 기술 스택을 사용하여 빠르게 개발할 수 있습니다.
- EC2를 ASG(Auto Scaling Group)에 배치하여 트래픽 증가에 대비할 수 있고, RDS 또한 Read Replica를 배치할 수 있습니다.

현재 이런 구조를 지니게 되었습니다.
2. 모두에게 보내는 공지사항 알림 뿐 아니라 특정 작업 완료 시 개인에게 보내는 알림 서비스를 구현할 것
해당 요구사항을 만족하기 위해 다양한 레퍼런스를 찾아보며 고민했습니다. Spring Batch 또는 Scheduler를 이용한 구현, Apache Kafka를 이용한 구현, RDB에 토큰 정보를 저장하는 방법 등 아주 많은 방향이 있더군요.
이렇게 서비스를 구축한 레퍼런스를 찾은 것은 아니지만, 저는 AWS Lambda, DynamoDB, Eventbridge Scheduler 등의 서비스를 사용하기로 했습니다.
AWS Lambda를 적극적으로 사용한다.
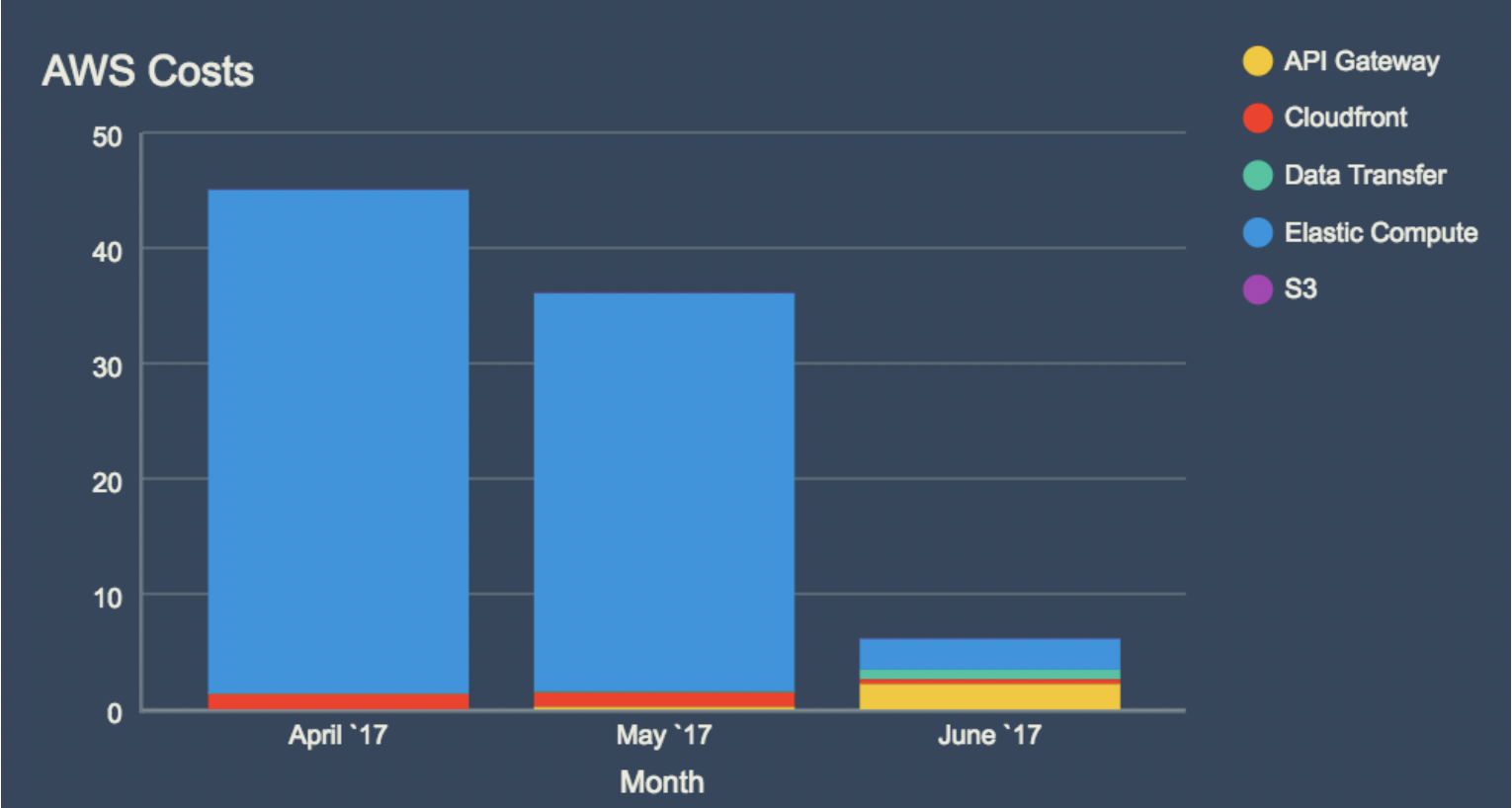
AWS의 서버리스 서비스들은 (대부분) 엔트리 레벨에서 저렴한 가격을 제공합니다.
AWS가 관리하는 서비스이기 때문에 제가 직접 관리할 것이 줄어들어 안정성이 높고, 빠르게 구현할 수 있습니다.
하지만 원론적으로 매니징 하지 않는 서비스보다 매니지드 서비스가 비싼 것이 사실입니다.
AWS Lambda의 경우 월 1백만건의 요청이 무료이기 때문에 처음에 보면 가격적인 엄청난 메리트가 있다고 느껴지지만, 서비스의 규모와 트래픽이 늘어남에 따라 이후엔 비용이 아주 커질 수 있습니다. 성능적 한계도 있을 수 있습니다. 이미 트래픽이 늘어난 상황에서 마이그레이션을 하는 것은 큰 부담일 것입니다. (관리형 서비스에 클라이언트를 가두는거죠.)
어쨌든 저의 입장에서는 저정도로 대규모 트래픽을 갖게 될 것이라고 추측되지 않고, 프리티어가 넉넉하기 때문에 서버리스 서비스를 아주 잘 이용할 수 있겠습니다.
따라서 저는 AWS Lambda를 기반한 아키텍처 구조를 가져가고자 했습니다.
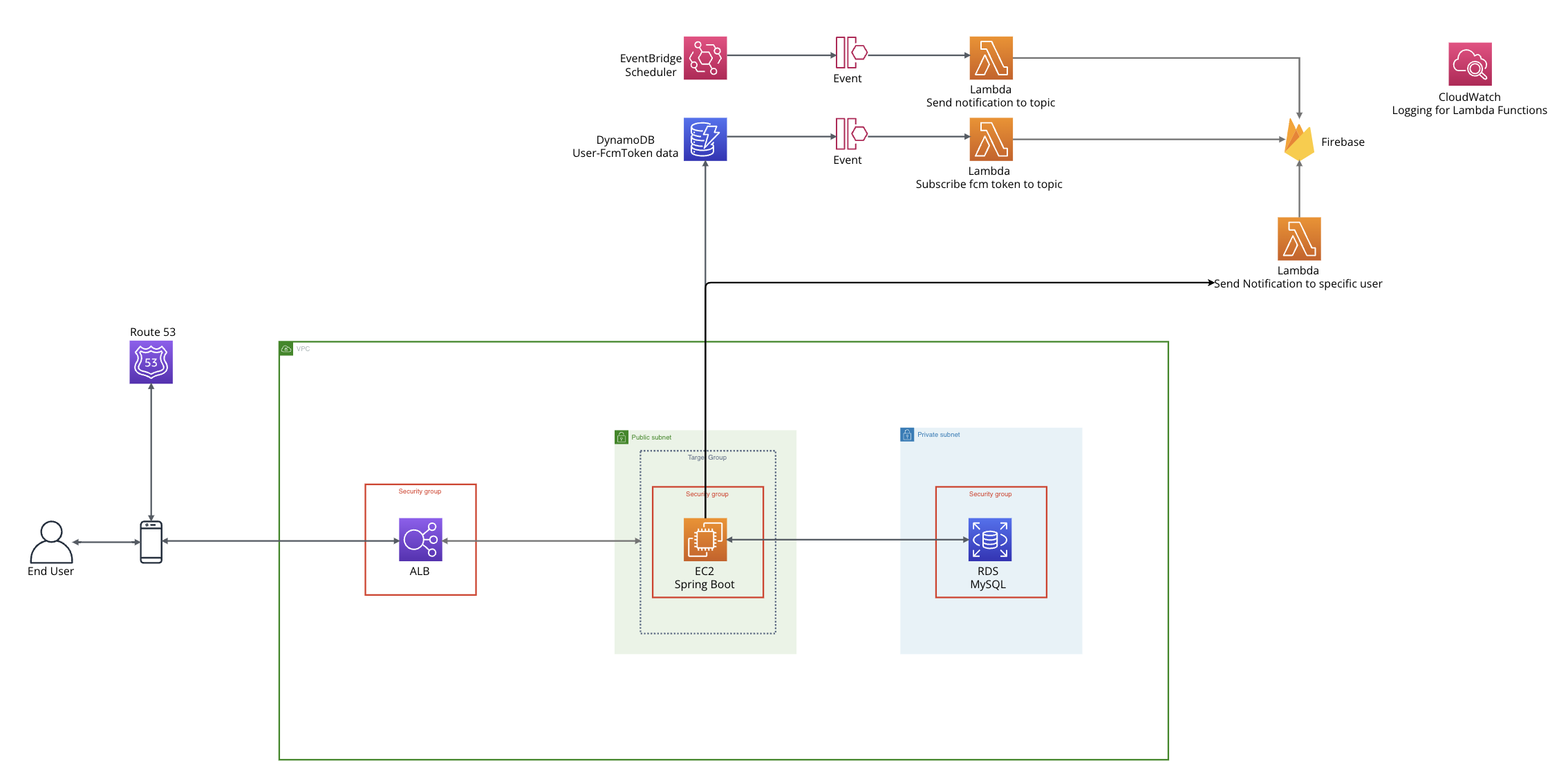
다음과 같은 설계를 하였습니다.
- FCM 토큰 정보를 DDB에 저장하고, Event Stream을 통해 Lambda로 보내 FCM 토큰을 topic에 구독시킨다.
- EventBridge Scheduler로 정기 알림을 보내도록 설정한다.
- 개인 유저의 토큰 정보를 조회하여 유저에게 알림을 보낼 수 있도록 구성한다.
이러한 설계로 제가 얻을 수 있었던 장점은 다음과 같습니다:
- DDB, Lambda, EventBridge Scheduler 모두 과금 요소가 매우 적거나 없습니다. 따라서 비용 효율성을 챙겼습니다.
- AWS가 관리하는 서비스들을 적극적으로 이용하여 구현 속도가 다른 방법에 비해 월등히 빠릅니다.
- Spring Batch와 같은 서비스 구현과 달리 EC2의 리소스를 사용하지 않으므로 효율적입니다.
3. 외부 API(GPT)를 호출할 수 있고, 이는 비동기적으로 호출할 것
DayCarat 서비스는 유저로부터 컨텐츠를 받을때마다, 이를 기반으로 GPT를 통한 데이터 가공 과정을 거칩니다. 그런데 왜 이 과정을 비동기적으로 진행해야 할까요?

스프링 부트 서버에서 호출한다고 가정합시다. 유저가 스프링 서버로 컨텐츠를 업로드하면, 스프링 서버에서 직접 GPT에 요청을 보내 응답을 받을때까지 기다린 후 응답이 돌아오면 가공된 데이터를 저장합니다. 스프링 부트 서버만으로 비동기적인 호출 구현이 가능합니다. @Async 어노테이션을 사용하거나 WebClient를 사용하는 등의 방법으로 처리하면 스레드가 블록되지 않고 다른 작업을 계속할 수 있어 요구사항을 만족할 수 있지만, 저는 좀 더 우아하게 구현하고자 했습니다.
디커플링
메인 WAS와 데이터 가공 컴포넌트를 분리하여, 데이터 가공 모듈에 오류가 발생해도 애플리케이션 서버에 악영향을 끼치지 않도록 구성하고자 했습니다. 외부 API를 호출하는 만큼 오류에 유연하게 대응할 수 있어야 한다고 판단했습니다. 그러려면 EC2 이외의 리소스를 할당해야 했고, 앞서 언급한 서버리스 서비스들을 적극 이용하기로 했습니다.
오류 핸들링
이 부분 또한 중요한 고려 사항이었습니다. 저는 GPT API를 그 당시 처음 접했는데, 원하는 양식대로 받아오는 일이 여간 쉽지 않았습니다. GenAI의 특징인데, 프롬프트를 열심히 작성해도 가끔씩 예외가 발생하기 때문입니다. 처음엔 단순히 프롬프트를 잘 작성하여 최대한 오류를 줄이자는 생각이었지만, 가끔씩 생기는 오류로 인해 사용자가 서비스에 신뢰를 잃을까 하는 걱정이 되었습니다.
Function Calling: 응답이 원하는 형태로 오지 않는 경우를 방지하지 위해, Function Calling 을 사용했습니다.
In an API call, you can describe functions and have the model intelligently choose to output a JSON object containing arguments to call one or many functions. The Chat Completions API does not call the function; instead, the model generates JSON that you can use to call the function in your code.
해당 기능을 이용하면 GPT 호출 시 사용자 정의 함수를 호출하기 위한 인자를 포함하는 응답을 JSON 형식으로 받아올 수 있습니다.
{
"type": "object",
"properties": {
"keywordId": {
"type": "integer",
"description": "키워드를 분류하여 반환한 숫자 1: 커뮤니케이션, 2: 문제 해결, 3: 창의성, 4: 도전 정신, 5: 전문성, 6: 실행력"
},
"generatedContent1": {
"type": "string",
"description": "한국어로 작성한 자기소개서에 쓸 수 있는 추천 문장 1 (200자 이상)",
},
"generatedContent2": {
"type": "string",
"description": "한국어로 작성 자기소개서에 쓸 수 있는 추천 문장 2 (200자 이상)",
},
"generatedContent3": {
"type": "string",
"description": "한국어로 작성한 자기소개서에 쓸 수 있는 추천 문장 3 (200자 이상)",
}
},
"required": ["keywordId", "generatedContent1", "generatedContent2", "generatedContent3"]
}(제가 사용했던 초안입니다. 예시로 보여드리고자 가져왔습니다.)
다음과 같이 데이터 스키마를 정의하여, 응답 포맷을 원하는 대로 받아올 수 있습니다. 이는 제가 만드는 서비스처럼 데이터 가공에 GPT가 사용되는 경우 굉장히 유용합니다. Function Calling을 이용하여 응답 포맷으로 인한 에러 발생 가능성을 아예 없앴습니다.
재시도 로직: S3 - SQS - Lambda 파이프라인을 구성하여 Lambda가 SQS의 메세지를 기반으로 데이터를 처리할 수 있도록 구성했습니다. EC2에서 사용자의 컨텐츠를 S3로 업로드하면, S3 이벤트로 인해 SQS 메세지가 생기고, Lambda는 SQS로부터 이벤트를 받아 S3의 컨텐츠를 읽어 GPT 호출을 실행합니다.
Lambda는 호출을 한 후, Validation 과정을 거쳐 유효한 응답이 아니라면 (가령, 카테고리 id가 유효하지 않은 경우 예외 발생) 에러를 던지며 다시 람다 함수를 실행함으로써 재시도를 합니다. 이를 통해 데이터 가공의 성공률을 크게 높일 수 있었습니다.

다이어그램으로 표현하면 이와 같습니다.
- 현재까지 사용한 로직에 추가적인 비용 발생이 없습니다: 굉장히 비용 효율적입니다.
- 디커플링을 통해 데이터 가공 컴포넌트가 메인 서버에 영향을 주지 않음으로써 단일 장애 지점을 회피하였습니다.
- 서버리스 서비스를 적극적으로 사용하여 빠르게 구현해낼 수 있습니다.
4. 팀원과 원활한 소통을 할 수 있도록 고려할 것
새로운 서비스를 빼르게 개발해나가기 위해선 클라이언트 개발자가 원활히 개발할 수 있도록 백엔드 개발자가 적극적으로 도와주어야 합니다. 현업과 다르게 이러한 프로젝트에서는 클라이언트 개발자의 부담이 비교적 큽니다. 그렇다면 제가 어떤 방식으로 개발을 도울 수 있을까요?
Swagger
스웨거는 API 문서를 제공하는 굉장히 효율적인 수단입니다.

스웨거 문서를 사용하여 개발 상황을 한눈에 알아볼 수 있고, 직접 Web UI로 API 테스트를 진행할 수 있습니다. 어떤 문제가 서버의 문제인지 클라이언트의 문제인지 판단할 때 Swagger를 이용하여 빠르게 API 테스트를 진행할 수 있다는 장점이 있습니다. 저처럼 여러 프로그램을 한꺼번에 켜두며 개발하는 개발자의 경우, Postman과 같은 별도의 프로그램을 켜두지 않아도 API 테스트를 진행할 수 있다는 점 또한 매력적입니다.
Slack API
슬랙 API를 이용하여 정말 다양한 기능을 구현할 수 있습니다. 저는 공지사항 관리 기능과 에러 로그 출력을 이를 이용하여 구현했습니다.
에러 로그 출력: Spring의 Logback을 이용하여 구성했습니다. 에러 발생 시 Slack의 Webhook url을 통해 특정 채널로 메세지가 가도록 구성했습니다.

다음과 같이 에러 로그를 실시간으로 보낼 수 있도록 구성하여, 클라이언트 개발자가 직접 확인할 수 있도록 하였습니다. 이러한 설정을 통해 제가 연락을 받지 못하는 상황이어도 어느정도의 에러 핸들링이 가능해졌습니다.
공지사항 관리 가능:편리하게 공지사항을 관리할 수 있도록 슬랙에서 기능을 제공했습니다.
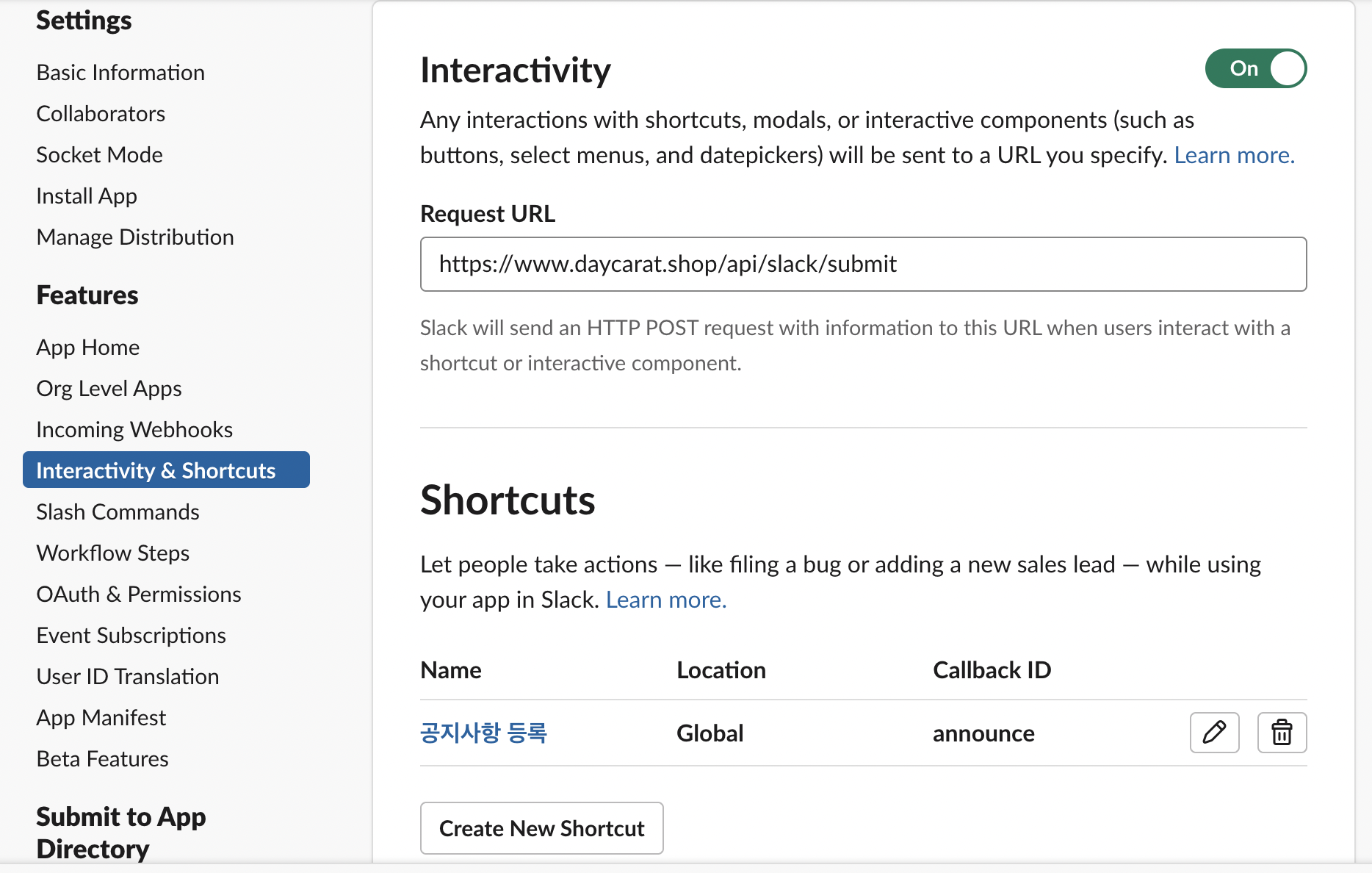
Slack API 페이지에서 다음과 같이 다양한 Interactivity를 제공하는 기능이 있습니다. 이를 통해 직접적으로 WAS - Slack API 서버 통신이 가능하여, 별도로 Slack API를 위한 서버 구축 없이 기존 WAS에 슬랙과 기능 연동이 가능합니다. 서버와 소통을 할 때 커스텀 포맷을 받기 위해 설정이 가능한데, 이에 대한 자세한 게시글은 수요가 있다면 따로 올리도록 하겠습니다.
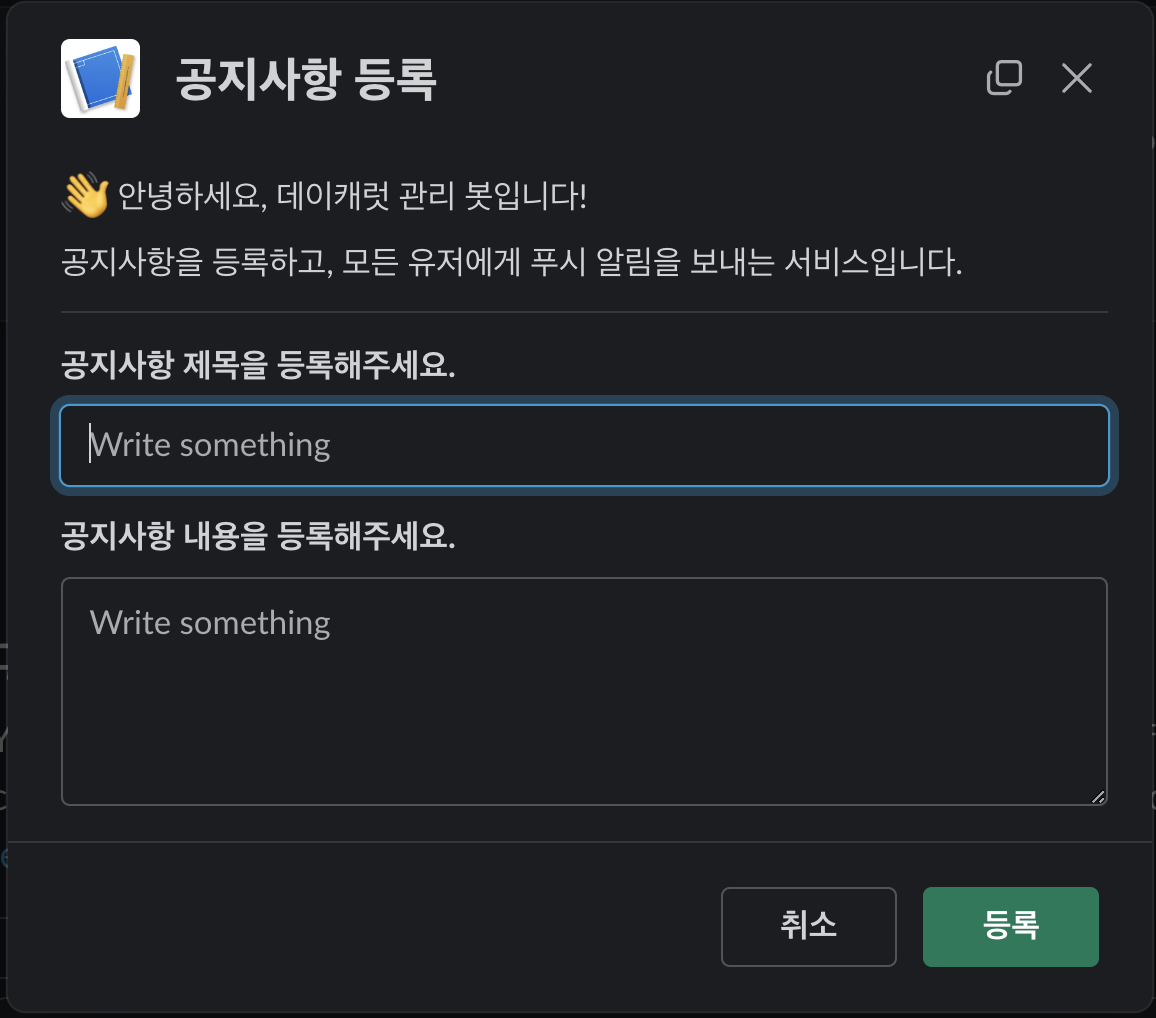
결과적으로 이처럼 원하는 양식으로 슬랙에 기능 추가를 할 수 있었고, 프로젝트 매니저님이 개발자를 거치지 않아도 서비스에 직접적으로 개입할 수 있도록 구성했습니다.
서버 아키텍처

그래서 최종적으로 저의 아키텍처는 다음과 같습니다. 그림을 보며 기타 고려사항에 대해 말씀드리겠습니다.
왜 EC2를 public subnet에 배치하였는가?
사실 EC2를 Public subnet에 두는 것이 좋은 것은 아닙니다. 하지만 제가 이렇게 설정한 것에는 두가지 이유가 있었습니다.
- Gitub Actions를 사용한 CICD 구현: 깃헙액션 워크플로우를 통해 CICD를 구현하는데, private subnet에 두면 이것이 불가능합니다(...) AWS Code시리즈를 통한 CICD를 구축하는 등 다른 방향도 있었지만, 제한된 시간 내에 빠르게 구축하고자 익숙한 Github Actions 를 채택하였고, 그러려면 Public subnet에 EC2를 배치해야 했습니다.
- NAT Gateway 비용 부담: private subnet에 배포 시 기본적으로 Internet connectivity가 없습니다. 따라서 NATGW를 설치하여 이를 통해 인터넷 엑세스를 해야 하는데, 특히 이미지 레포지토리에서 이미지를 받아오는데 소요되는 트래픽이 컸고, 이로 인한 비용 부담이 예상됐습니다(특히 개발 단계이므로 배포가 엄청 자주 이루어지는 점을 고려했습니다.)
public subnet에 배치하여 생길 수 있는 보안적 이슈는 SG과 NACL로 보완하였습니다.
당시 나름의 근거를 세워 위 그림과 같이 구현하였지만 지금 생각엔 다음과 같이 개선할 수 있을 것 같습니다:
- AWS Code series: 이를 이용하면 private subnet에 EC2를 배치해도 CICD 구현이 가능합니다. 다음번에 프로젝트를 진행한다면 이 서비스들을 이용할 것 같습니다.
- VPC Interface Endpoint (PrivateLink): ECR 이미지 레포지토리에서 이미지를 가져올 때 VPC Endpoint를 사용한다면 NAT 비용 없이 가져올 수 있을 것으로 기대합니다. 그렇다면 비용적 부담도 덜을 수 있을 것 같습니다. S3로 업로드하는 경우에도 VPC Gateway Endpoint를 사용한다면 내부 네트워크에서 처리할 수 있습니다
마무리
결과적으로 DayCarat 서비스를 구축하여 프리티어 범위 내에서 꽤 많은 기능을 구축했고, 모든 요구사항을 만족했습니다. 굉장히 뿌듯한 경험이었으며, 큰 규모의 아키텍처를 다를 수 없는 저의 입장에서 나름 재미있고 우아하게 문제를 해결했다고 생각합니다. 하지만 여기서 만족해선 안됩니다. 저는 오늘도 꾸준히 공부하며, 매일 새로운 것을 배우며 과거의 잘못된 선택에 대해 깨닫습니다. 이 아키텍처도 보완할 점이 아주 많습니다. 허나 저는 촉박한 시간에 해당 서비스를 무사히 구현해낼 수 있었음에 만족하며, 이번 프로젝트는 대성공이었다고 말하고 싶습니다. 긴 글 읽어주셔서 감사합니다.
https://github.com/Central-MakeUs/DayCarat-Server
GitHub - Central-MakeUs/DayCarat-Server: 💎 커리어 경험 기록 관리 서비스 DayCarat
💎 커리어 경험 기록 관리 서비스 DayCarat. Contribute to Central-MakeUs/DayCarat-Server development by creating an account on GitHub.
github.com