Hello,
After earning several AWS certifications, I developed an interest in AWS questions in AWS re:Post.

However, manually checking for new questions was tedious when I wasn't actively viewing the page. So, I decided to automate the process of retrieving new questions using a web crawler and sending notifications through Slack.
Architecture

The architecture is as follows:
- An EventBridge Scheduler periodically invokes the Lambda function.
- The Lambda function fetches HTML from the AWS re:Post page.
- It checks DynamoDB to see if the URL has already been processed and updates the information accordingly.
- It notifies about new questions or accepted answers via Slack.
Before we start
When using web crawlers, it's essential to check for legal issues related to bot usage on websites. An easy way to do this is by reviewing the site's robots.txt file.
You can check this by adding "/robots.txt" to the domain name. Many websites use this path to indicate whether crawling is permitted.
For example, here is the robots.txt file for AWS re:Post:
https://repost.aws/robots.txt

Currently, they allow crawling of the '/' path, which includes the '/questions' path, for all user agents. So, let's get started!
Configure AWS Lambda
We're using AWS Lambda for compute resource. AWS Lambda is a powerful service that is fully managed by AWS, and it scales automatically. Let's have a brief look at the snippet of the code:
# Constants
REPOST_URL = 'https://repost.aws/questions?view=all&sort=recent'
REPOST_URL_KO = 'https://repost.aws/ko/questions?view=all&sort=recent'
# Environment variables for sensitive information
SLACK_WEBHOOK_URL = os.environ['SLACK_WEBHOOK_URL']
SLACK_API_TOKEN = os.environ['SLACK_API_TOKEN']
SLACK_CHANNEL = os.environ['SLACK_CHANNEL']
DYNAMODB_TABLE_NAME = os.environ['DYNAMODB_TABLE_NAME']
USER_AGENT = os.environ['USER_AGENT']
EMAIL = os.environ['EMAIL']
# Initialize DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(DYNAMODB_TABLE_NAME)
# Initialize Slack client
slack_client = WebClient(token=SLACK_API_TOKEN)
# Define headers for the HTTP request
headers = {
'User-Agent': USER_AGENT,
'From': EMAIL
}
- REPOST_URL indicates the URL we want to crawl. I also added REPOST_URL_KO because I want questions in Korean.
- Initialization of DynamoDB and Slack Client is handled outside the lambda_handler function. For optimizing the Lambda function code, refer to the following documentation.
- header represents the HTTP Header. When crawling, the User-Agent and From headers are specified to provide information so that if our crawling bot causes issues to the website, they can contact me.
Now let's look at each function:
def fetch_new_questions(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
question_list = soup.find('div', class_='ant-row ant-row-start')
questions = question_list.find_all('div', class_='QuestionCard_card__E3_x5 QuestionCard_grid__0e3xB')
new_questions = []
for question in questions:
question_url = 'https://repost.aws' + question.find('a')['href']
question_text = question.find('a').text.strip()
question_accepted_tag = question.find('span', class_='ant-tag CustomTag_tag__kXm6J CustomTag_accepted__VKlHK')
new_questions.append((question_url, question_text, question_accepted_tag is not None))
return new_questions
This function actually makes a request to the re:Post website and parses the response. I inspected the class names of the elements from the HTML response, and then the function returns questions.
Here, you can see question_accepted_tag is not None. This is an ACCEPTED_ANSWER tag in re:Post. Through this tag, we can check whether the question has already been answered and handle the accepted questions accordingly.
def check_question_in_db(question_url):
response = table.get_item(Key={'url': question_url})
return 'Item' in response
def add_question_to_db(question_url):
table.put_item(Item={'url': question_url})
def update_question_accepted_in_db(question_url, accepted):
table.update_item(
Key={'url': question_url},
UpdateExpression="set accepted=:val",
ExpressionAttributeValues={':val': accepted}
)
def notify_slack(question_text, question_url):
print(f"New Question: {question_text}\nURL: {question_url}")
try:
response = slack_client.chat_postMessage(
channel=SLACK_CHANNEL,
text=f"New Question: {question_text}\nURL: {question_url}"
)
return response['ts'] # Slack timestamp of the message
except SlackApiError as e:
print(f"Error sending message to Slack: {e.response['error']}")
return None
def update_slack_message_with_emoji(question_text):
try:
# Fetch recent messages from the Slack channel
response = slack_client.conversations_history(channel=SLACK_CHANNEL, limit=100)
messages = response['messages']
# Search for the message containing the question_text
for message in messages:
if question_text in message['text']:
ts = message['ts']
slack_client.reactions_add(
channel=SLACK_CHANNEL,
timestamp=ts,
name='white_check_mark'
)
break
except SlackApiError as e:
print(f"Error adding reaction to Slack message: {e.response['error']}")
We use Boto3, the AWS SDK for python, to connect with DynamoDB.
Here's a brief description of the functions:
- check_question_in_db: This function checks if a question URL already exists in the database. It returns True if the URL is found, otherwise False.
- add_question_to_db: This function adds a new question URL to the database.
- update_question_accepted_in_db: This function updates the status of a question in the database, setting whether it has been accepted or not.
- notify_slack: This function sends a notification to a specified Slack channel with the text of the question and its URL. It returns the timestamp of the Slack message if successful.
- update_slack_message_with_emoji: This function searches recent messages in the Slack channel for a message containing the given question text and adds a "white_check_mark" emoji reaction to it.
def lambda_handler(event, context):
new_questions = fetch_new_questions(REPOST_URL)
new_questions += fetch_new_questions(REPOST_URL_KO)
for question_url, question_text, question_accepted_tag in new_questions:
if not check_question_in_db(question_url):
add_question_to_db(question_url)
ts = notify_slack(question_text, question_url)
if ts:
table.update_item(
Key={'url': question_url},
UpdateExpression="set slack_ts=:ts",
ExpressionAttributeValues={':ts': ts}
)
else:
# Check if the question has an accepted answer and update Slack
response = table.get_item(Key={'url': question_url})
if response['Item'].get('accepted'):
print(f"Already marked as accepted: {question_text}")
elif question_accepted_tag:
print("Accepted answer:", question_text)
# Update the Slack message with an emoji
update_slack_message_with_emoji(question_text)
# Update the accepted status in the database
update_question_accepted_in_db(question_url, True)
return {
'statusCode': 200,
'body': 'Lambda function executed successfully'
}
This is the Lambda handler. The Lambda handler calls predefined functions to perform tasks. First, it retrieves questions from the web page and checks if the URL is already in DynamoDB. If it's a new question not present in DynamoDB, it inserts the question into DynamoDB and sends a Slack message.
For questions already checked in DynamoDB, it checks the ACCEPTED_TAG. If the question has been accepted, it sets is_accepted to true in DynamoDB and configures the Slack message to include an emoji.
Configure DynamoDB

You can create a simple table to use as a URL storage. If you're worried about the increasing data size, you can set TTL (Time to Live) for DynamoDB to expire outdated questions. For more information, check out the AWS Documentation.
NOTE: You have to give permission to DynamoDB from Lambda by adding a policy in the IAM role for Lambda. If you don't, the function will not work and will show an error message.
Configure EventBridge Scheduler

A simple EventBridge Scheduler to regularly invoke the Lambda function will do the job. You can specify the start time and end time to save costs.
Final Result
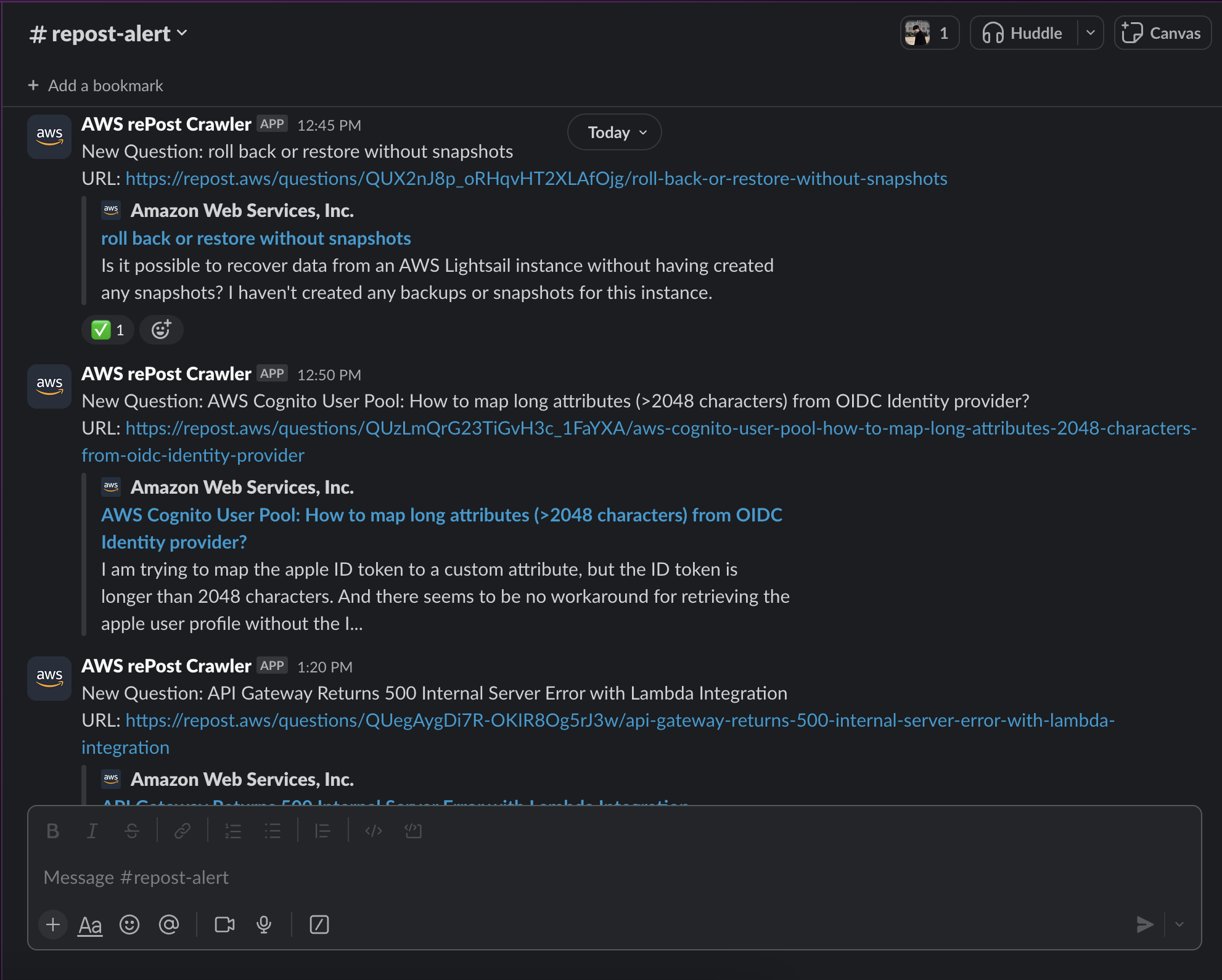
Ta-da! We've successfully created a simple web crawler. I used Slack API's incoming webhook for Slack integration. Remember to set the appropriate scope permissions for the Slack bot to add emojis. Why not create your own crawler bot to automate your tasks?
'AWS' 카테고리의 다른 글
| [KO]CloudFormation StackSets를 이용한 다중 계정 환경 관리! (0) | 2024.08.22 |
|---|---|
| [EN]Multi-account environment with CloudFormation StackSets (0) | 2024.08.16 |
| Terraform의 aws_iam_openid_connect_provider에 관하여 (0) | 2024.07.18 |
| [AWS IAM] Hands-on: Github Actions에 임시 자격 증명 사용하기 (0) | 2024.07.17 |
| [AWS IAM] Identity Federation & Cognito Basics (0) | 2024.07.16 |