처리율 제한 장치(rate limiter)의 설계를 공부한 내용을 정리했습니다.
Rate limiter란?
Rate limiter, 즉 처리율 제한 장치는 클라이언트 또는 서비스가 보내는 트래픽의 처리율(rate)을 제어하기 위한 장치이다.
e.g. 특정 기간 내 전송되는 클라이언트의 요청 횟수 제한
API 요청 횟수가 threshold를 넘어서면 추가로 도달한 요청은 모두 차단된다.
- 사용자는 초당 2회 이상 새로운 게시글을 올릴 수 없음
- 같은 IP 주소로는 하루에 10개 이상의 계정을 생성할 수 없음
- 같은 디바이스로는 주당 5회 이상 리워드를 요청할 수 없음
From Cloudflare – https://www.cloudflare.com/en-gb/learning/bots/what-is-rate-limiting/
Rate limiting is a strategy for limiting network traffic. It puts a cap on how often someone can repeat an action within a certain timeframe.
Rate limiting is fairly one dimensional: While useful, it can only stop very specific types of bot activity. Additionally, rate limiting is not just for bots, but for limiting usage in general. Cloudflare Rate Limiting, for instance, protects against DDoS attacks, API abuse, and brute force attacks, but it doesn't necessarily mitigate other forms of malicious bot activity, and it doesn't distinguish between good bots and bad bots.
왜 필요한가?
1. DoS / DDoS protection: DoS protection은 이해가 되는데, DDoS를 방지할 수 있나? 가능하다면 어떻게 하지?
https://www.netscout.com/what-is/rate-limiting
How Does Rate Limiting Work to Prevent DDoS Attacks?
Rate limiting is deployed to limit the level of abuse an attacker can release on an application, asset, or server to keep it available for all users. Malicious traffic can overwhelm a resource, preventing legitimate users from accessing it. Rate limiting achieves its goal by disallowing certain users, or groups of users, from monopolizing access to the asset and making it unavailable.
If attackers are bombarding a website with illegitimate malicious traffic in a volumetric DDoS attack, then it can take the website offline due to server overload. This prevents legitimate users from accessing the website, costing the business revenue and damaging its reputation, leading to future revenue losses. Rate limiting can aid in limiting the number of requests the malicious traffic generates by filtering by IP or location, allowing legitimate traffic to get through and continue business as usual.
별로 와닿지 않음
From ChatGPT:
Rate limiting isn’t useless in DDoS scenarios. It plays a supporting role:
1. Edge Rate Limiting (CDNs/WAFs):
Services like Cloudflare, AWS Shield, Akamai can enforce rate limits at the edge before traffic reaches your servers.
2. Intelligent Rate Limiting:
Based on behavioral patterns (e.g., anomaly detection, reputation scoring). Combined with geofencing, device fingerprinting, and CAPTCHA.
3. Per-Route or Resource-Specific Limits:
Limit access to costly resources (e.g., login or search endpoints) to prevent targeted exhaustion.
예를 들어 ML 기반으로 DDoS 공격을 감지하여 이를 기반으로 처리율을 제한하거나, route/resource 단위로 처리율을 제한해서 영향 받는 범위를 최소화 가능
2. 비용 절감
우선순위에 따라 자원 할당하도록 구성할 수 있음
3. 서버 과부하 방지
Initial considerations
- 어떤 종류의 rate limiter가 필요한가: 클라이언트 측 혹은 서버 측 제한 장치
- 어떤 기준을 사용하여 처리율을 제한할 것인가: IP 혹은 사용자 ID 등
- 시스템 규모가 어느정도인가
- 시스템이 분산 환경에서 동작해야 하는가
- Rate limiter를 독립된 서비스로 만들 것인가 혹은 애플리케이션 코드에 포함시킬 것인가
- 처리율 제한 장치에 의해 차단당한 경우 사용자가 그 사실을 알아야 / 알 수 있어야 하는가
-> 위 질문을 통해 요구사항을 specify 할 수 있음
- 설정된 처리율을 초과하는 요청은 정확하게 제한한다
- 낮은 응답시간: rate limiter가 HTTP response time에 영향을 주면 안됨
- 가능한 한 적은 메모리 사용
- distributed rate limiting: 하나의 처리율 제한 장치를 여러 서버/프로세스가 공유해서 사용 가능해야 함
- 예외 처리: 요청이 제한되었을 때 사용자에게 분명하게 보여주어야 함
- fault tolerance: rate limiter의 장애 여부가 전체 시스템에 영향을 주어선 안 됨
개략적 설계안
1. 어디에 둘 것인가
클라이언트 측에 둔다면: 일반적으로 클라이언트는 rate limiter를 안정적으로 걸 수 있는 장소가 아님. 클라이언트 요청은 쉽게 위변조가 가능하기 때문. 또한 통제가 어려움.
서버 측에 둔다면:
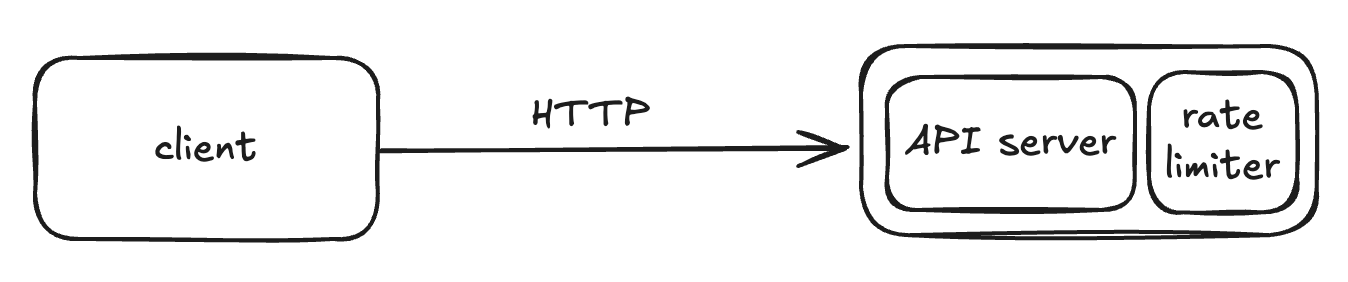
1) 서버 내에 rate limiter를 두는 방법

2) rate limiter를 middleware로 두는 방법
근데 1) 서버 내에 rate limiter를 두는 방법은 어떻게 구현하겠단건지 감이 안온다. 어쨌든 API 서버 앞에 두어야 하는 것 아닌가
From ChatGPT:
첫 번째 구조는 rate limiter를 API 서버 내부에 포함시키는 형태입니다.
- 보통 웹 프레임워크의 미들웨어(middleware) 혹은 handler 앞단 로직으로 구현합니다.
- 즉, 요청이 들어오면, API 핸들러로 가기 전에 rate limiter가 먼저 실행되어 요청을 판단하는 구조입니다.
- 내부적으로는 Redis나 In-Memory(token bucket, leaky bucket, sliding window 등)를 써서 구현합니다.
- 서버 내부에서 처리된다고 해도 결국 요청은 먼저 서버까지 도달해야 하므로, 이 구조는 서버 자원 소모의 리스크가 있습니다.
이해했음. 별도의 리소스를 구성한 건 아니고 API 서버에 포함시키지만, API 서비스 로직 앞에서 handler으로써 역할한다는거네
- rate limiter에서 차단된 요청은 보통 429 Too many requests 상태 코드를 알림
- 보통 클라우드 마이크로서비스 환경에서 rate limiter는 API gateway 단에서 구현됨
- APIGW는 보통 SSL termination, authentication, IP whitelist management 등을 담당하며, rate limiting도 지원함
rate limiter를 설계할 때 중요한 것 중 하나가 바로 이 리소스를 어디에 두어야 하는지이다. (서버에 둘 것인지, APIGW에 둘 것인지, ..) 이 때 고려할 사항은 아래와 같다:
- 프로그래밍 언어, 캐시 서비스 등 기술 스택을 점검하여 서버 측 구현이 가능한지 확인해야 함
- use case에 맞는 rate limiter 방식을 채택해야 함. 예를 들어, third-party gateway에 있는 rate limiter를 사용할 경우, 내부 알고리즘에 대한 선택지가 제한적임
- 서비스가 마이크로서비스 환경이고, 사용자 인증이나 IP 허용목록 관리 등을 처리하기 위해 APIGW를 이미 설계에 포함시켰다면 rate limiter를 APIGW에 포함시키는 것을 고려할 것
- rate limiter를 서버에 직접 구현하는 데는 시간이 든다. 구현할 cap이 없다면 관리형 APIGW를 쓰는 것이 바람직
처리율 제한 알고리즘
- token bucket
- leaky bucket
- fixed window counter
- sliding window log
- sliding window counter
Token bucket algorithm
많은 rate limiter가 채택중인 방식. 간단하며 보편적임. 아마존, 스트라이프가 API throttle을 관리하기 위해 사용한다고 함
토큰 버킷은 지정된 용량을 갖는 컨테이너다. 이 버킷에는 사전 설정된 양의 토큰이 주기적으로 채워짐. 토큰이 꽉 찬 버킷에는 더 이상의 토큰이 추가되지는 않음. -> 아 이거 t instance family credit이네
따라서 토큰이 없는 경우 요청이 drop 됨.
토큰 버킷 알고리즘은 두 개의 parameter를 사용
- bucket size: the maximum number of the token
- refill rate: how many token(s) will be filled per second
버킷은 몇 개나 사용해야 하나? -> 규칙에 따라 달라짐
- 통상적으로 API endpoint 당 하나의 버킷을 둠
- IP 주소별로 제한해야 한다면 IP 주소마다 버킷을 하나씩 할당해야 함
- 전체 시스템의 처리율을 제한한다면, 모든 요청이 하나의 버킷을 공유하도록 구성
장점:
- 구현이 쉬움
- 메모리 사용 측면에서도 효율적
- burst of traffic도 처리 가능
단점:
- 단시간에 많은 트래픽이 몰리는 경우 큐에 오래된 요청들이 쌓이게 되고, 그 요청들을 제때 처리 못하면 최신 요청들이 버려짐
- bucket size/refill rate을 적절히 조정하기 까다로움
Leaky bucket algorithm
누출 버킷(leaky bucket) 알고리즘은 토큰 버킷 알고리즘과 비슷하지만 요청 처리율이 고정되어 있다는 점이 다르다. FIFO 큐로 구현한다.
- 요청이 도착하면 큐가 가득 차 있는지 본다. 빈자리가 있는 경우 큐에 요청을 추가한다.
- 큐가 가득 차 있는 경우 새 요청은 버린다.
- 지정된 시간마다 큐에서 요청을 꺼내어 처리한다.

-> 여기 drop된 요청을 보내는 큐를 DLQ라고 하기보다는 Retry / Delay / Backoff Queue 라고 부른다고 한다.
누출 버킷 알고리즘은 두 개의 parameter를 사용
- bucket size
- outflow rate: 지정된 시간당 몇 개의 항목을 처리할지 지정하는 값. X requests per Y second
Shopify가 해당 알고리즘을 사용함
장점
- 큐의 크기가 제한되어 있어 메모리 사용량 측면에서 효율적임
- 고정된 처리율을 가지고 있어 안정적 출력이 필요한 경우 적합함
단점
- 단시간에 많은 트래픽이 몰리는 경우 큐에는 오래된 요청이 쌓이게 되고, 그 요청들을 제때 처리 못하면 최신 요청들은 버려짐
- 두 개의 인자를 갖고 있는데, 이들을 올바르게 튜닝하기 까다로울 수 있음
Fixed window counter algorithm
고정 윈도 카운터 알고리즘은 다음과 같이 동작한다.
- timeline을 고정된 간격의 window로 나누고, 각 window마다 counter를 붙인다.
- 요청이 접수될 때마다 이 카운터의 값은 1씩 증가한다.
- 이 카운터의 값이 사전에 등록된 threshold에 도달하면 새로운 요청은 새 window가 열릴 때까지 버려짐

문제는 특정 구간 당 카운팅을 하기 때문에, window의 경계 부근에 트래픽이 몰리는 경우 많은 양의 트래픽이 허용될 수 있다.
-> 이론상 한 period 내 예상한 한도 * 2의 요청이 허용될 수 있음
장점
- 메모리 효율이 좋음
- 이해하기 쉬움
- window가 닫히는 시점에 카운터를 초기화하는 방식은 특정한 트래픽 패턴을 처리하기에 적합함
단점
- window 경계 부근에서 일시적으로 많은 트래픽이 몰리는 경우, 고정된 time window를 기반으로 동작하기에 위 사진처럼 많은 양의 요청이 차단되지 않고 처리될 수 있음
Sliding window log algorithm
time window를 움직이는 방식으로, 최신 시점 + X seconds를 time window로 설정
- 요청의 timestamp를 추적하며, 이 타임스탬프 데이터는 보통 redis의 sorted set 같은 캐시에 보관함
- 새 요청이 오면 만료된 timestamp는 제거함. 만료된 timestamp는 그 값이 현재 window 시작 지점보다 오래된 timestamp를 의미함
- 새 요청의 timestamp를 log에 추가함
- 로그의 크기가 허용치보다 같거나 작으면 요청을 시스템에 전달함. 그렇지 않은 경우 처리를 거부함
장점
- fixed window counter 알고리즘의 단점에서 명시된 문제 (window 경계에 걸친 requests로 인해 많은 요청이 허용되는 문제)를 해결
단점
- 다량의 메모리를 사용함.
Sliding window counter algorithm
fixed window counter와 sliding window log 알고리즘을 합한 방식으로, 현재 시점에 걸쳐있는 이전 time window의 비중과 요청 수를 퍼센트로 계산한다. 계산 방법은 아래와 같다.
- 현재 1분간의 요청 수 + 직전 1분간의 요청 수 * sliding window와 직전 1분이 겹치는 비율
장점
- 이전 시간대의 평균 처리율에 따라 현재 window 상태를 계산하므로, 짧은 시간에 몰리는 트래픽에서 잘 대응할 수 있다.
- 메모리 효율이 좋다.
단점
- 직전 시간대에 도착한 요청이 균등하게 분포되어 있다고 가정한 상태에서 추정치를 계산하기 때문에 예외 케이스가 있을 수 있다. 다만 실제로 Cloudflare에서 진행한 테스트 결과 이러한 예외 케이스가 0.003%정도로 굉장히 적었음다고 한다.
개략적인 아키텍처
얼마나 많은 요청이 수집되고 있는지 추적하기 위한 카운터를 추적 대상별로 둔다 (추적 대상은 endpoint, 혹은 IP 주소 등)
이 카운터를 데이터베이스에 보관하기엔 다소 느려서 권장되지 않는다. 메모리상 동작하는 캐시가 바람직하며, 시간에 기반한 만료 정책을 설정할 수 있기 때문에 좋다. Redis는 rate limiter를 구현할 때 자주 사용되는 메모리 기반 저장장치로써, INCR와 EXPIRE 명령어를 지원한다.
- INCR: 메모리에 저장된 카운터의 값을 1만큼 증가시킴
- EXPIRE: 카운터에 타임아웃 값을 설정한다. 설정된 시간이 지나면 카운터가 자동으로 삭제된다.

따라서 카운터 값의 관리를 redis에서 담당한다.
상세 설계
처리율 한도 초과 트래픽의 처리
어떤 요청이 threshold를 넘어서면 API는 HTTP 429 Too many requests 응답을 클라이언트에게 보낸다. 경우에 따라 한도 제한에 걸린 메세지를 나중에 처리하기 위해 큐에 보관할 수 있다 (Retry / Delay / Backoff Queue).
처리율 제한 장치가 사용하는 HTTP 헤더
클라이언트가 자신의 요청이 처리율 제한에 걸리고 있는지 확인하기 위해 쓰이는 HTTP 헤더가 있다.
- X-Ratelimit-Remaining: 현재 window 내 남은 요청 수
- X-Ratelimit-Limit: window 마다 가능한 요청 수
- X-Ratelimit-Retry-After: 한도 제한에 걸리지 않으려면 몇 초 후 요청을 보내야 하는지 알려줌
따라서 설계 시 해당 헤더들 값을 채우도록 설계하면 좋다.
아키텍처
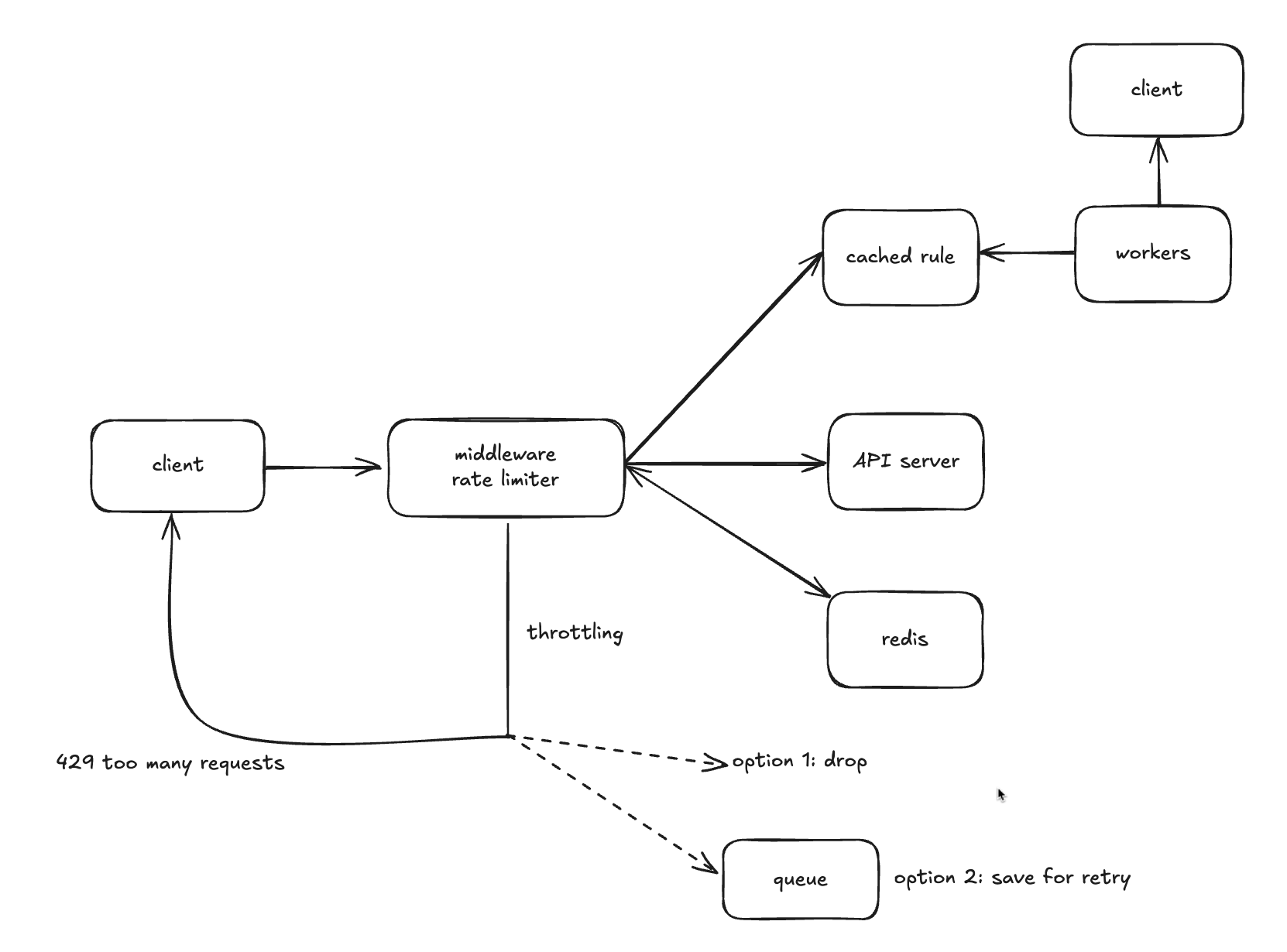
- 처리율 제한 규칙은 디스크에 보관한다. worker는 수시로 규칙을 디스크에서 읽어 캐시에 저장한다.
- 클라이언트가 요청을 서버에 보내면 요청은 먼저 처리율 제한 미들웨어에 도달한다.
- 처리율 제한 미들웨어는 제한 규칙을 캐시에서 가져온다. 아울러 카운터 및 마지막 요청의 timestamp를 레디스 캐시에서 가져온다. 가져온 값들에 근거하여 해당 미들웨어는 다음과 같은 결정을 내린다.
- 해당 요청이 처리율 제한에 걸리지 않으면 API 서버로 요청을 보낸다.
- 제한에 걸릴 경우 option 1) drop 하거나 option 2) 큐에 보낸다. 응답으로는 429 too many requests 를 보낸다.
분산 환경에서의 rate limiter 구현
분산 환경에서는 아래 두 가지 사항을 고려해야 한다.
- race condititon
- 여러 서비스가 공유된 redis에 접근하기 때문에, race condition을 고려해야 한다. 가장 쉬운 방법은 lock 이지만, 이는 시스템의 성능을 상당히 떨어뜨린다. 따라서 락 대신 사용할 수 있는 방법은 1) Lua script를 사용하는 것과 2) sorted set 자료구조를 사용하는 것이 있다.
- Lua script: (ChatGPT) Redis는 하나의 스레드로 명령을 처리합니다. 따라서 Lua 스크립트 내부에서 실행되는 모든 명령은 원자적(atomic)입니다. 즉, 여러 명령을 하나의 트랜잭션처럼 묶어 동시성 문제 없이 처리할 수 있습니다.
- Sorted set: (ChatGPT) Rate limit을 일정 시간 동안의 요청 수로 정의하고, 그 요청의 타임스탬프를 ZADD 명령으로 sorted set에 저장합니다. 이후 일정 시간 전의 요청들을 ZREMRANGEBYSCORE로 제거하고, 현재 남은 요청 수를 기준으로 rate limit 여부를 판단합니다.
- synchronization
- 여러 대의 rate limiter를 사용한다면 이들간 동기화도 중요한 문제다. 웹 계층은 stateless 이므로 요청마다 각기 다른 rate limiter로 요청을 보낼 수 있다.
- sticky session을 사용할 수 있다. 다만 이 방법은 단순히 특정 기준으로 요청을 고정시키는 (stateful 하게 만드는) 방식이기 때문에 확장성이 떨어지고 유연하지 않다. 이를 해결하기 위해 중앙 집중형 저장소를 사용할 수 있다. (커다란 레디스 하나..)
Token bucket을 직접 만들어보자!
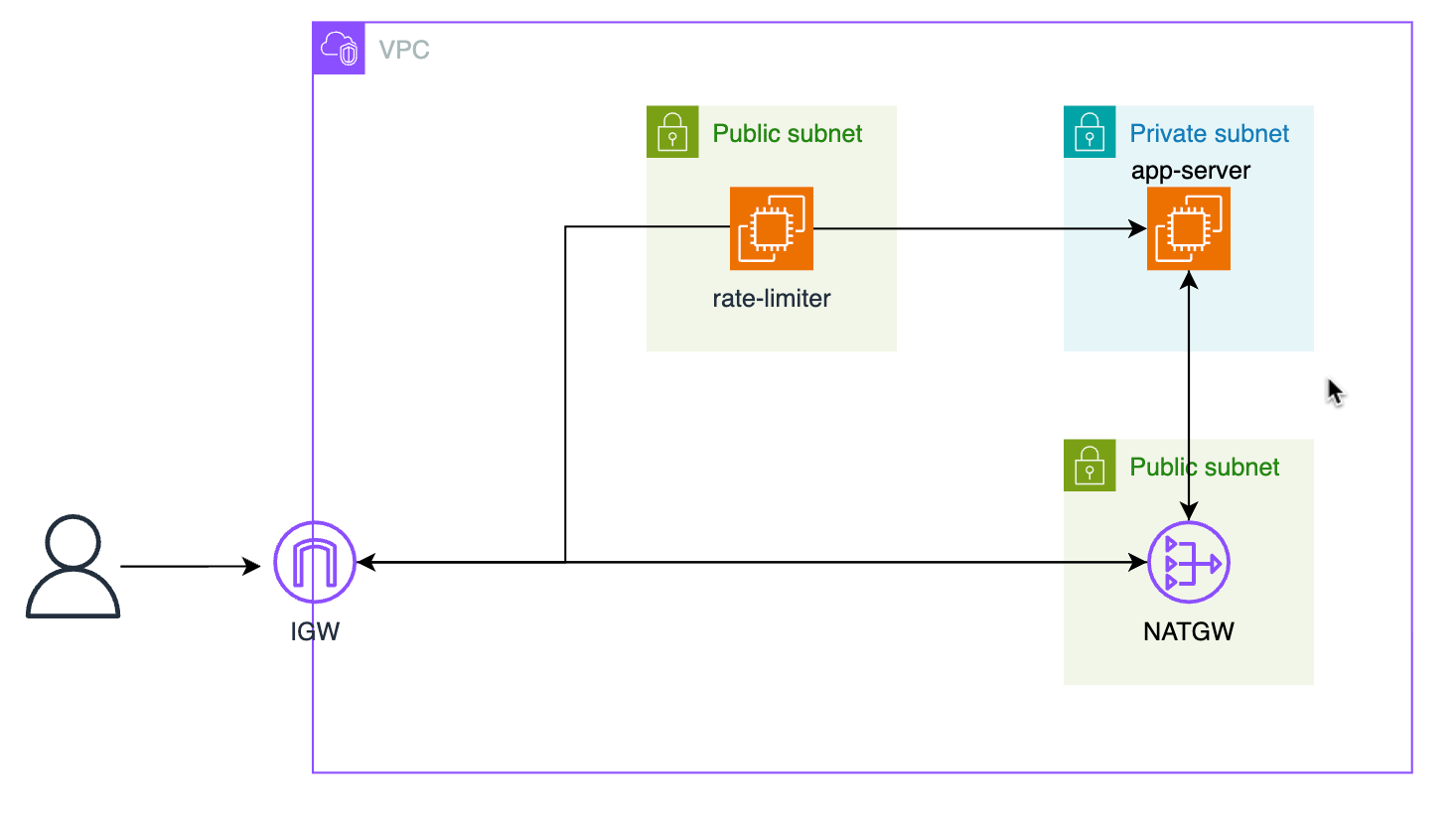
rate limiter 중 가장 보편적으로 쓰이는 token bucket algorithm 방식을 이용해 rate limiter를 만들어보았습니다.
rate-limiter는 was 앞에서 middleware로써 req를 대신 받아주는 구조를 띄고 있습니다.
rate_limiter에서 동작하는 함수는 아래와 같습니다:
class TokenBucketRateLimiter:
def __init__(self, tokens_per_second, bucket_size):
self.tokens_per_second = tokens_per_second
self.bucket_size = bucket_size
self.buckets = defaultdict(lambda: {
'tokens': bucket_size,
'last_update': time.time()
})- 토큰 버킷 알고리즘 기반 rate limiter 클래스를 정의합니다.
- IP 주소별로 각각 다른 토큰 버킷을 저장하도록 구성하였습니다.
- tokens_per_second: 초당 추가되는 토큰 수
- bucket_size: 버킷에 담을 수 있는 최대 토큰 수
- last_update: 마지막으로 토큰을 업데이트한 시간
def _update_tokens(self, ip):
now = time.time()
bucket = self.buckets[ip]
time_passed = now - bucket['last_update']
new_tokens = time_passed * self.tokens_per_second
bucket['tokens'] = min(self.bucket_size, bucket['tokens'] + new_tokens)
bucket['last_update'] = now- 버킷을 갱신하는 함수로, 마지막 업데이트 이후 경과 시간에 따라 토큰을 충전합니다.
- 최대 bucket_size를 초과하지 않도록 제한합니다.
- 따라서 매 초마다 토큰 값이 업데이트 되는 것이 아니라, 요청이 올 때 마다 마지막 요청 시간을 기준으로 계산하도록 구현합니다. 실제로도 이렇게 동작할 것 같습니다 (굳이 매번 cron 작업을 돌리면서 낭비할 이유는 없으니까요!)
def is_allowed(self, ip):
with self.lock:
self._update_tokens(ip)
bucket = self.buckets[ip]
if bucket['tokens'] >= 1:
bucket['tokens'] -= 1
return True
return False- 현재 요청이 허용 가능한지 판단하는 함수입니다.
- 토큰이 1개 이상이면 요청을 허용허면서 토큰을 1개 차감합니다.
- 남아있는 토큰이 없다면 429 Too many requests 응답을 보냅니다.
limiter = TokenBucketRateLimiter(tokens_per_second=10, bucket_size=20)
WEB_APP_URL = "http://" + os.environ.get("WEB_APP_PRIVATE_IP") + ":8080"- 실제 rate limiter 위와 같이 initialize 하며, 요청 시 is_allowed 함수를 통해 버킷의 토큰 수를 체크하며 요청을 차단할지 결정합니다.
뒷단 app-server는 그냥 평범한 flask 서버이며, 단순한 요청/응답을 주고받는 서버입니다. 미들웨어인 rate-limiter를 테스트하는 것이 목적이므로 해당 서버에 대한 설명은 생략합니다.
def test_rate_limiter(url):
print(f"Testing rate limiter at {url}")
print("Sending 10 requests...\n")
for i in range(40):
try:
response = requests.get(url)
status = "SUCCESS" if response.status_code == 200 else f"FAILED ({response.status_code})"
print(f"Request {i+1}: {status}")
except Exception as e:
print(f"Request {i+1}: ERROR - {str(e)}")
time.sleep(0.02)- 해당 코드는 외부(제 컴퓨터)에서 rate limiter가 제대로 동작하는지 테스트하기 위해 사용할 스크립트입니다. 아주 간단하게 url에 대해 0.02초마다 한번씩 http req을 날립니다. 실행 결과..

- 실행 결과 위와 같이 한 ip에서 빠른 속도로 burst request가 오면 rate limiter에 의해 요청이 차단되는 것을 확인할 수 있습니다.
이렇게 간단하게 token bucket algorithm이 어떻게 구현되는지 알아보았습니다. 봐주셔서 감사합니다 : )
'Server > System Design' 카테고리의 다른 글
| Review: Software Architecture & Design of Modern Large Scale Systems (1) (0) | 2025.11.24 |
|---|---|
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 8장: URL 단축기 설계 (0) | 2025.06.22 |
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 7장: 분산 시스템을 위한 유일 ID 생성기 설계 (0) | 2025.06.21 |
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 6장: 키-값 저장소 설계 (1) | 2025.06.19 |
| 가상 면접 사례로 배우는 대규모 시스템 설계 기초 5장: 안정 해시 설계 (0) | 2025.06.16 |